Regression Testing
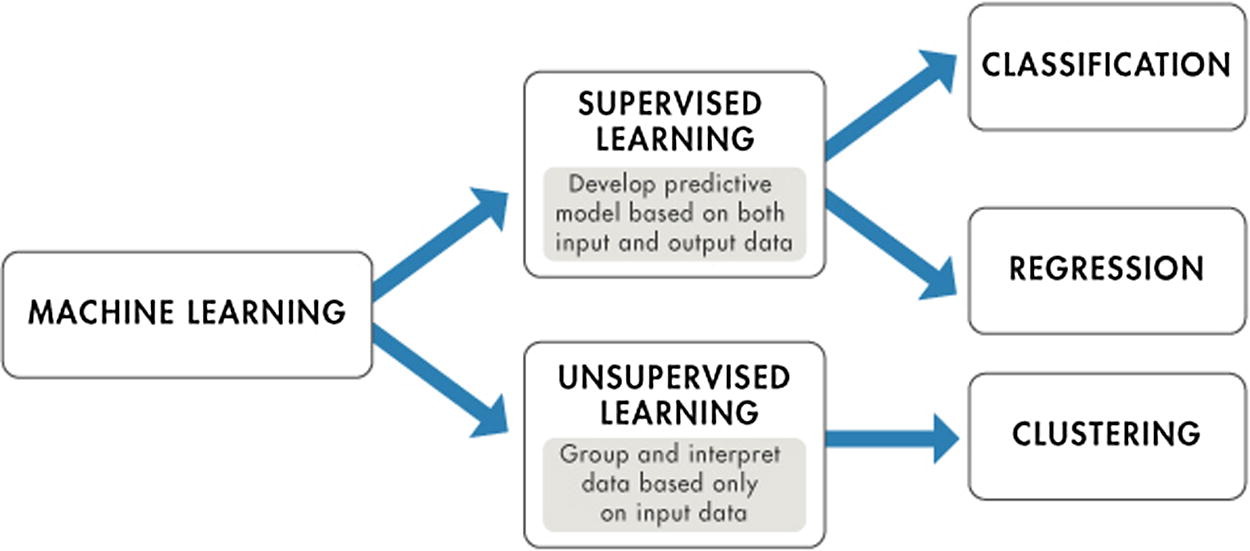
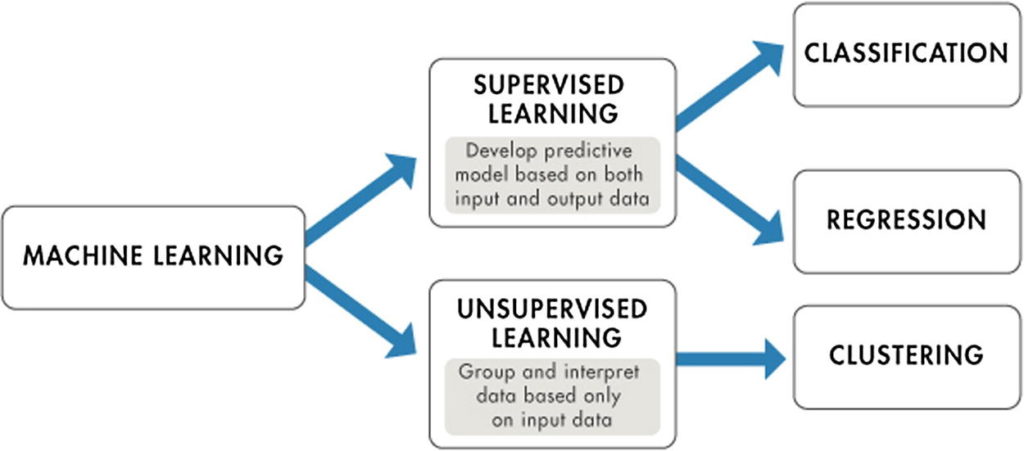
One of the common machine learning (ML) tasks, which involves predicting a target variable in previously unseen data, is classification. The aim of classification is to predict a target variable (class) by building a classification model based on a training dataset, and then utilizing that model to predict the value of the class of test data. This type of data processing is called supervised learning since the data processing phase is guided toward the class variable while building the model. Some common applications for classification include loan approval, medical diagnoses, email filtering, among others.
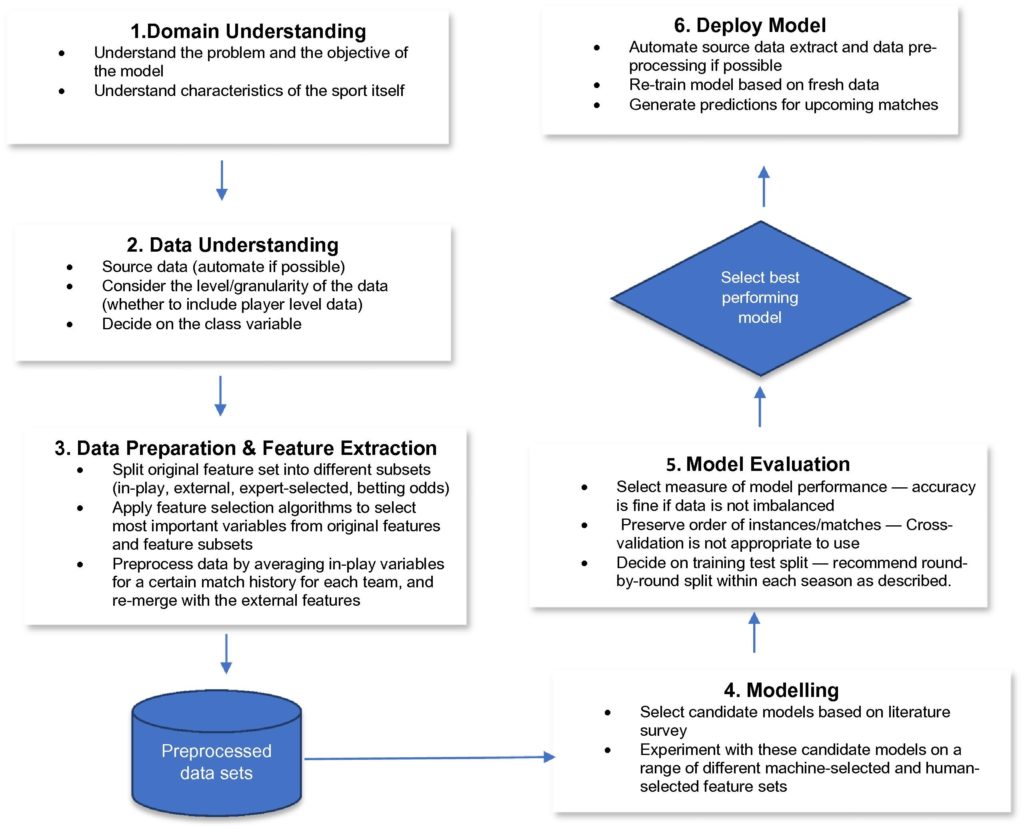
Sports prediction is usually treated as a classification problem, with one class (win, lose, or draw) to be predicted. Although some researchers have also looked at the numeric prediction problem, where they predict the winning margin – a numeric value. In sports prediction, large numbers of features can be collected including the historical performance of the teams, results of matches, and data on players, to help different stakeholders understand the odds of winning or losing forthcoming matches. The decision of which team is likely to win is important because of the financial assets involved in the betting process; thus bookmakers, fans, and potential bidders are all interested in approximating the odds of a game in advance. Once a predicted result for the match is obtained, an additional problem is to then decide whether to bet on the match, given the bookmaker’s odds. In addition, sport managers are striving to model appropriate strategies that can work well for assessing the potential opponent in a match. Therefore, the challenge of predicting sports results is something that has long been of interest to different stakeholders, including the media. The increasing amount of data related to sports that is now electronically (and often publically) available, has meant that there has been an increasing interest in developing intelligent models and prediction systems to forecast the results of matches.